
iPhone可跑2B小钢炮!谷歌Gemma 2来袭,最强显微镜剖解LLM大脑
iPhone可跑2B小钢炮!谷歌Gemma 2来袭,最强显微镜剖解LLM大脑谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。
来自主题: AI技术研报
10898 点击 2024-08-01 15:32
 搜索
搜索
谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。

刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!

MH-MoE 能优化几乎所有专家,实现起来非常简单。
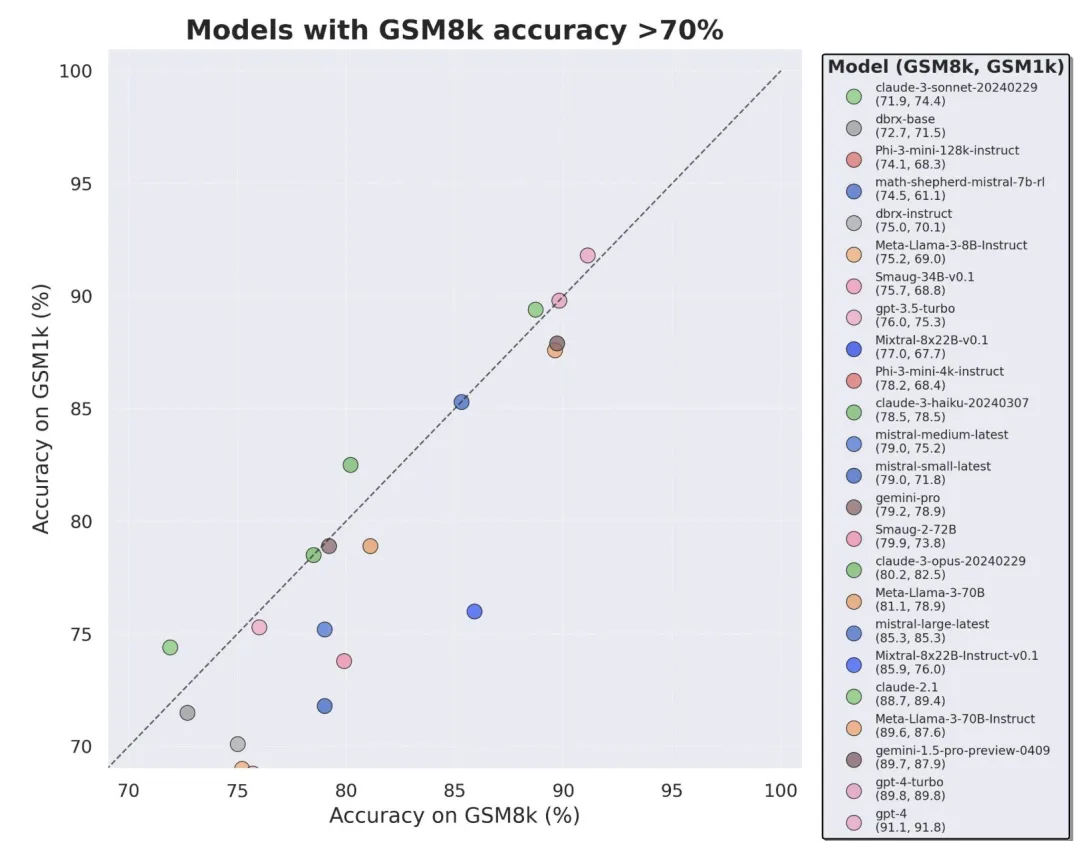
当前最火的大模型,竟然三分之二都存在过拟合问题?

Mixtral 8x7B模型开源后,AI社区再次迎来一大波微调实践。来自Nous Research应用研究小组团队微调出新一代大模型Nous-Hermes 2 Mixtral 8x7B,在主流基准测试中击败了Mixtral Instruct。
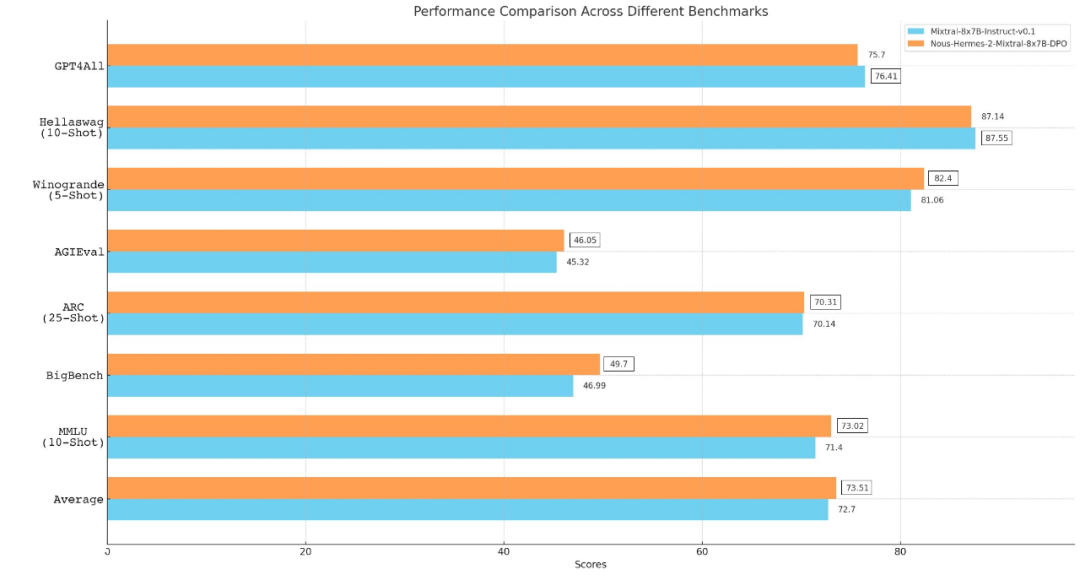
从 Llama、Llama 2 到 Mixtral 8x7B,开源模型的性能记录一直在被刷新。由于 Mistral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5,因此它也被认为是一种「非常接近 GPT-4」的开源选项。

爆火社区的Mixtral 8x7B模型,今天终于放出了arXiv论文!所有模型细节全部公开了。
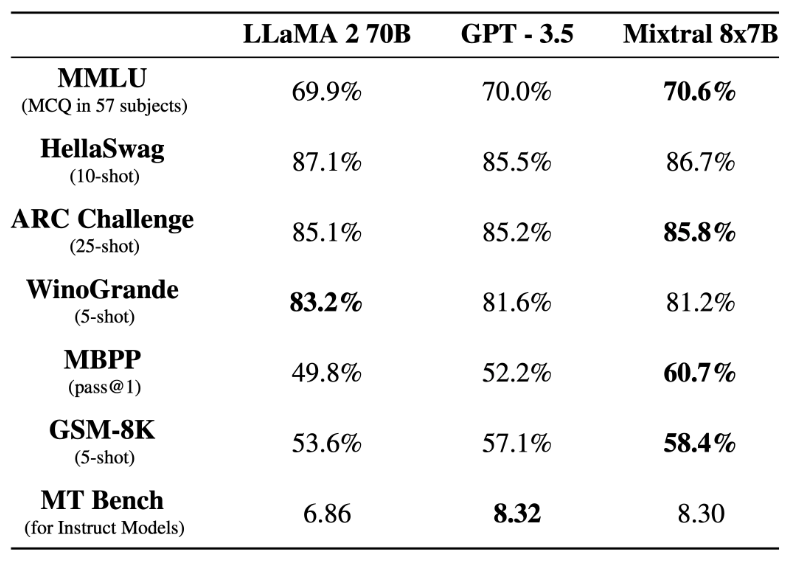
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。

彭博社报道,Mistral 正在完成 4.87 亿美元的融资,估值 20 亿美元,其中英伟达、Salesforce 参与,a16z 领投。

一条神秘磁力链接引爆整个AI圈,现在,正式测评结果终于来了:首个开源MoE大模型Mixtral 8x7B,已经达到甚至超越了Llama 2 70B和GPT-3.5的水平。